NLP 基础学习笔记:引论及正则表达式
NLP 基础学习笔记 01:引论以及正则表达式
1 NLP 引论
NLP ( Natural Language Processing, 自然语言处理 ) 是计算机领域以及人工智能领域的一个重要研究方法,它研究通过计算机来处理人类语言,以达到使计算机 “理解” 自然语言语义的目的 。通过 NLP 相关技术,使人类能更自由地由计算机进行 “通讯”。同时,这项技术也被应用于海量数据处理领域,如:舆情分析、知识图谱等。
本系列学习笔记将基于 Pytorch,整理、记录、总结 NLP 相关基础知识,包括中文分词 ( Segment )、词性标注 ( Tagging )、命名实体识别 ( NER, Named Entity Recoginition )、关键词提取、句法分析 ( Syntax Parsing )、文本向量化、情感分析等方面 ( Emotion Recognition )。
2 正则表达式
正则表达式,又称正规表达式,是一种以文字串来描述,符合其特定语法的表达式形式。其可以用于检索、字符串匹配等方面。正则表达式是处理自然语言的最基本的手段之一,其可以帮助我们抽取文本中所需的特定信息。
2.1 常用正则表达式语法
2.1.1 普通字符
普通字符一般带有双括号 [ ] ,表示直接对括号中的内容进行匹配 。
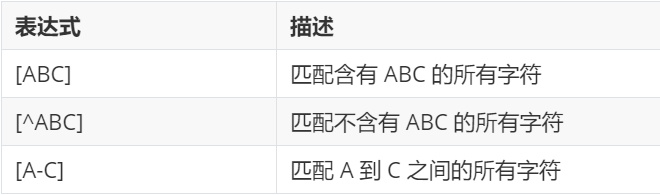
2.1.2 特殊字符
特殊字符一般不在双括号中,表示某种逻辑含义。
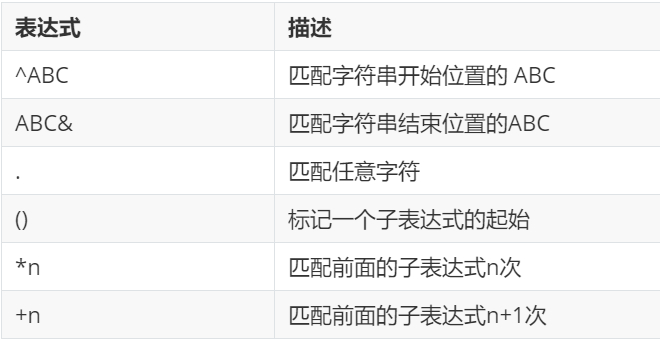
以上仅为常用的部分正则表达式语法,完整的语法手册请查询:
3 在 python 中使用正则表达式
在 Python 中通过 re 模块来实现正则表达式,本篇主要介绍 re.match 函数以及 re.search 函数。
re.match
re.match 函数尝试从字符串的开始匹配模式串,若匹配成功,则返回一个 match 对象,否则则返回 none。
函数原型
1 | match(pattern, string, flags=0) |
其中,pattern 为模板正则表达式,string 为待匹配的字符串,flags 为用于控制正则表达式匹配方式的标志。
样例代码
1 | import re |
执行结果
1 | 网络爬虫又称为网页蜘蛛 |
re.search
re.search 函数在整个模板串中进行匹配,若匹配上,则返回一个 match 对象;反之则返回 none。
函数原型
1 | search(pattern, string, flags=0) |
与 match 函数基本相同。
样例代码
1 | import re |
执行结果
1 | 网络爬虫又称为网页蜘蛛 |
使用转义符
当我们需要匹配字符串中的一些符号,如 \ , [] 等,需要对其进行转义,使其失去原本在正则表达式中的特殊含义。与其他大多数语言相通,正则表达式采用反斜杠 \ 进行转义。