论文笔记:TTS Key Components
论文笔记:TTS Key Components
论文原文地址:https://arxiv.org/abs/2106.15561
1. 分类
我们主要从基本 TTS 组件的角度对 TTS 的工作进行分类,这包括:文本分析(Text analysis),声学模型(Acoustic models),声码器(Vocoders),完全端到端模型(Fully end-to-end models)。这种分类方式描述了从文本到声学波形的处理过程:
- 文本分析:将字符转换为音素(phoneme)或者语言学特征
- 声学模型:从音素或语言学特征生成声学特征
- 声码器:将声学特征转换为波形
- 完全端到端模型:将字符或音素直接转换为波形
因此,我们可以整理出TTS工作的数据流:字符,语言特征,声学特征,波形。
2. 文本分析
文本分析通常被认为是TTS的前端(frontend),其将输入文本转化为语言特征,包含有关发音和韵律的丰富信息。在统计参数合成(statistic parametric synthesis)中,文本分析用于提取特征向量序列,并包含一些功能,如:文本归一化,分词,词性标注,韵律预测,以及字素到音素转换。在端到端模型中,由于模型强大的建模能力,字符可以直接作为模型的输入,但在这种情况下,仍然需要进行文本归一化以获得单词格式。并且,还需要进行字素到音素转换以从标准单词格式中获得音素。尽管一些TTS模型声称其可以直接从字符生成波形,仍然需要进行文本归一化以防任何可能的非标准格式原始文本。此外,一些端到端TTS模型集成了传统的文本分析功能,例如:Char2Wav和Deep Voice,在其处理管线中加入了字符到语言特征的处理能力,完全基于神经网络。一些模型使用文本编码器(encoder)预测韵律特征。
3. 声学模型
随着TTS模型的发展,不同类型的声学模型被采用,例如应用于SPSS(Statistical parametric speech synthesis)的基于HMM,DNN的早期模型,和基于encoder-attention_decoder框架的Seq2Seq模型(包括LSTM,CNN和self-attension),和最新的用于并行生成的前馈网络(CNN或self-attention)。
声学模型的目的是生成声学特征,以便交由声码器处理。声学特征很大程度上决定了TTS管线的种类。不同类型的声学特征已被尝试过,如:MCC,MGC,BAP,F0,V/UV,BFCC,和最广泛使用的 mel-spectrograms。因此,我们可以将声学模型分成两个时期:
- SPSS中的声学模型,通常从语言特征预测MGC、BAP和F0等声学特征;
- 基于神经网络的端到端TTS中的声学模型,从音素或字符中预测声学特征,如mel-spectrograms等;
在SPSS中,统计模型如HMM,DNN或RNN被用来从语言特征生成声学特征(语音参数),生成的语音参数通过声码器转换成语音波形。这些声学模型的发展受以下几点驱动:
- 使用更多的上下文信息作为输入;
- 对输出帧之间的相关性进行建模;
- 更好地解决过度平滑的预测问题;
在Yoshimura等、Tokuda等的研究中,HMM被用来生成语音参数(speech parameters),其中HMM的观测向量由频谱参数向量组成,如MCC和F0。与串联语音合成相比,基于HMM的参数合成在改变说话人身份、情感和说话风格方面更加灵活。基于HMM的SPSS的一个主要缺点是合成语音的质量不够好,主要有以下两个原因:
- 准确性不够好,主要是由于HMM的建模能力不足,预测的声学特征过度平滑且缺乏细节;
- 声码技术不够好;
因此,提出了基于DNN的声学模型,以提高合成质量。后来,为了更好地建模语音表达中的长时间跨度上下文效应,利用基于LSTM的循环神经网络来更好地建模上下文依赖性。随着深度学习的发展,一些先进的网络结构,如CBHG,被用来更好地预测声学特征。VoiceLoop采用“音韵循环”从音素序列生成声学特征(,然后使用WORLD 声码器从这些声学特征合成波形。或利用GAN来改善声学特征的生成质量。Wang等的研究探索了一种更端到端的方法,利用基于注意力的循环序列转录器模型,直接从音素序列生成声学特征,这可以避免逐帧对齐的需求。
与SPSS中的声学模型比起来,基于神经网络的端到端TTS中的声学模型有一些优势:1)传统的声学模型需要语言特征和声学特征之间的对齐,而基于序列到序列的神经模型通过注意力机制或联合预测持续时间来隐式学习对齐,这更具端到端性,需要较少的预处理。2)随着神经网络建模能力的增强,语言特征被简化为仅字符或音素序列,而声学特征从低维度且压缩的倒谱(例如MGC)变为高维度的梅尔频谱图或甚至更高维度的线性频谱图。在接下来的段落中,我们介绍一些代表性的神经TTS声学模型。
基于RNN的模型(如:Tacotron)
Tacotron利用编码器-注意力-解码器框架,以字符作为输入,输出线性频谱图,并使用Griffin-Lim算法生成波形。Tacotron 2 被提出以生成梅尔频谱图,并利用额外的WaveNet模型将梅尔频谱图转换为波形。Tacotron 2在语音质量上大大提高了声音的质量,相比串联TTS、参数化TTS和Tacotron等神经TTS方法。之后,许多研究从不同方面改进了Tacotron:1)使用参考编码器和风格标记来增强语音合成的表达能力,例如GST-Tacotron和Ref-Tacotron。2)去除Tacotron中的注意力机制,而是使用持续时间预测器进行自回归预测,例如DurIAN和非注意力Tacotron。3)将Tacotron中的自回归生成改为非自回归生成,例如Parallel Tacotron 1/2。4)基于Tacotron构建端到端的文本到波形模型,例如Wave-Tacotron。
基于CNN的模型(如:DeepVoice)
DeepVoice实际上是一个通过卷积神经网络增强的SPSS系统。DeepVoice通过神经网络获取语言特征,然后利用基于WaveNet 的声码器生成波形。DeepVoice 2遵循DeepVoice的基本数据转换流程,并通过改进的网络结构和多说话人建模增强了DeepVoice。此外,DeepVoice 2还采用了Tacotron + WaveNet模型流水线,首先使用Tacotron生成线性频谱图,然后使用WaveNet生成波形。DeepVoice 3利用全卷积网络结构进行语音合成,从字符生成梅尔频谱图,并可以扩展到真实世界的多说话人数据集。DeepVoice 3通过使用更紧凑的序列到序列模型,并直接预测梅尔频谱图而不是复杂的语言特征,改进了之前的DeepVoice 1/2系统。之后,提出了ClariNet ,以完全端到端的方式从文本生成波形。ParaNet是一个完全基于卷积的非自回归模型,可以加快梅尔频谱图的生成速度,并获得合理的语音质量。DCTTS与Tacotron共享类似的数据转换流程,并利用基于全卷积的编码器-注意力-解码器网络从字符序列生成梅尔频谱图。然后,它使用频谱图超分辨率网络获取线性频谱图,并使用Griffin-Lim 合成波形。
基于Transformer的模型(如:FastSpeech)
TransformerTTS利用encoder-attention-decoder架构从音素生成梅尔频谱图。他们认为,像Tacotron 2这样基于RNN的encoder-attention-decoder模型存在以下两个问题:1)由于循环的特性,无法并行训练RNN-based编码器和解码器,并且RNN-based编码器无法在推理中并行,这影响了训练和推理的效率。2)由于文本和语音序列通常非常长,RNN不擅长建模这些序列中的长期依赖关系。TransformerTTS采用了Transformer的基本模型结构,并吸收了Tacotron 2的一些设计,如解码器的预网络/后网络和停止标记预测。它在声音质量上与Tacotron 2相当,但训练时间更快。然而,与基于RNN的模型(如Tacotron)相比,后者利用了稳定的注意力机制(如位置敏感注意力),Transformer中的编码器-解码器注意力由于并行计算的缘故不够稳定。因此,一些工作提出了增强Transformer-based声学模型鲁棒性的方法。例如,MultiSpeech通过编码器归一化、解码器瓶颈和对角线注意力约束来提高注意力机制的鲁棒性,而RobuTrans利用持续时间预测来增强自回归生成的鲁棒性。
上述的声学模型都采用了自回归生成的方法,但存在推理速度慢以及鲁棒性差的问题。因此,FastSpeech被提出以解决这些问题。它采用前向传播的Transformer网络并行生成梅尔频谱图,大大加快了推理速度。它去除了文本和语音之间的注意力机制,以避免跳词和重复问题。它使用长度调节器来弥合音素序列和梅尔频谱图序列之间的长度不匹配的问题。长度调节器利用持续时间预测来预测每个音素的持续时间,并根据音素的持续时间扩展音素隐藏序列。扩展后的音素隐藏序列与梅尔频谱图序列的长度匹配,便于并行生成。FastSpeech的优点:
- 极快的推理速度:在生成梅尔频谱图上推理速度提高了270倍,在生成波形上提高了38倍;
- 生成的语音合成没有跳词和重复问题
- 声音质量与之前的自回归模型相当
4. 声码器
粗略地说,声码器的发展可以分为两个阶段:统计参数语音合成(SPSS)中使用的声码器以及基于神经网络的声码器。在SPSS中,一些流行的声码器包括STRAIGH和WORLD。我们以WORLD声码器为例,它包括声码器分析和声码器合成两个步骤。在声码器分析中,它分析语音并获取声学特征,如梅尔倒谱系数、带通不规则性和F0。在声码器合成中,它根据这些声学特征生成语音波形。在本节中,我们主要回顾基于神经网络的声码器的工作,因为它们效果更好。早期的神经声码器,如WaveNet、Char2Wav和WaveRNN,直接将语言特征作为输入并生成波形。后来的模型将梅尔频谱图作为输入,并生成波形。由于语音波形非常长,自回归式波形生成需要较长的推理时间。因此,在波形生成中使用了生成模型,如Flow、GAN、VAE和DDPM。因此,我们将神经声码器分为不同的类别:1)自回归声码器,2)Flow-based声码器,3)基于GAN的声码器,4)基于VAE的声码器,5)基于Diffusion的声码器。
自回归声码器
WaveNet是第一个基于神经网络的声码器,它利用扩张卷积来自回归地生成波形点。与SPSS中的声码器分析和合成不同,WaveNet几乎不包含关于音频信号的先验知识,完全依赖端到端学习。WaveNet生成基于语言特征的语音波形,可以轻松适应线性频谱图和梅尔频谱图作为条件。尽管WaveNet实现了较好的语音质量,但推理速度较慢。因此,许多工作研究轻量级和快速的声码器。SampleRNN利用分层循环神经网络进行无条件波形生成,并进一步集成到Char2Wav中以生成基于声学特征的波形。此外,WaveRNN用于高效的音频合成,利用循环神经网络并利用双重softmax层、权重剪枝和子缩放技术等多种设计来降低计算量。LPC-Net将传统的数字信号处理引入神经网络,并利用线性预测系数来计算下一个波形点,同时利用轻量级的RNN计算残差。LPCNet生成基于BFCC(巴克频率倒谱系数)特征的语音波形,并可以轻松适应梅尔频谱图作为条件。一些后续的工作从不同角度进一步改进了LPCNet,例如减少复杂性以提高速度,改进稳定性以提高质量。
Flow based Vocoder
Normalizing Flow 是一种生成模型。它通过一系列可逆映射来转换概率密度。根据变量变换规则,我们可以通过这些可逆映射的序列获得标准化的概率分布(例如高斯分布)。这种基于流的生成模型被称为归一化流。在采样过程中,通过这些变换的逆过程从标准概率分布生成数据。神经TTS中使用的基于流的模型可以分为两类:
- 自回归变换:例如在Parallel WaveNet中使用的逆自回归流;
- 双分区变换:例如在WaveGlow中使用的Glow,以及在FloWaveNet中使用的RealNVP;
自回归变换和双分区变换都有各自的优势和劣势:1)自回归变换通过建模数据分布x和标准概率分布z之间的依赖关系,比双分区变换更具表达能力,但在训练中需要复杂的教师蒸馏过程。2)双分区变换具有更简单的训练流程,但通常需要更多的参数(例如更深的层次、更大的隐藏层大小)才能达到与自回归模型相当的容量。为了结合自回归变换和双分区变换的优势,WaveFlow提供了一个基于似然的音频数据模型的统一视图,明确地将推理并行性与模型容量进行了交换。通过这种方式,WaveNet、WaveGlow和FloWaveNet可以看作是WaveFlow的特例。
基于GAN的声码器
GAN已经被广泛地用于数据生成任务,例如图像生成、文本生成和音频生成。GAN包括一个生成器用于数据生成,以及一个判别器用于判断生成数据的真实性。许多声码器利用GAN来确保音频生成的质量,包括WaveGAN、GAN-TTS、MelGAN、Parallel WaveGAN、HiFi-GAN以及其他基于GAN的声码器。
基于Diffusion的声码器
基本思想是利用扩散过程和逆过程来建立数据和潜在分布之间的映射:在扩散过程中,波形数据样本逐步添加一些随机噪声,最终变为高斯噪声;在逆过程中,随机高斯噪声逐步去噪成波形数据样本。基于扩散的声码器能够生成具有非常高质量的语音,但由于长时间的迭代过程,推理速度较慢。因此,许多关于扩散模型的工作正在研究如何在保持生成质量的同时减少推理时间。
5. 完全端到端TTS
完全端到端的TTS模型可以直接从字符或音素序列生成语音波形,它具有以下优点:1)需要较少的人工注释和特征开发(例如,文本和语音之间的对齐信息);2)联合和端到端优化可以避免级联模型中的错误传播(例如,文本分析+声学模型+声码器);3)它还可以减少训练、开发和部署成本。
然而,以端到端方式训练TTS模型面临着很大的挑战,主要是由于文本和语音波形之间的不同形式以及字符/音素序列与波形序列之间的巨大长度不匹配。例如,对于一个长度为5秒、含有约20个单词的语音,音素序列的长度大约只有100,而波形序列的长度为80k(如果采样率为16kHz)。由于内存的限制,很难将整个句子的波形点放入模型训练中。如果仅使用一个短音频片段进行端到端训练,很难捕捉到上下文表示。
由于完全端到端训练的困难,神经TTS的发展遵循逐步推进的过程,朝着完全端到端模型迈进。下图展示了从早期的统计参数合成开始的这一渐进过程。朝着完全端到端模型的过程通常包括以下升级:1)简化文本分析模块和语言特征。在SPSS中,文本分析模块包含不同的功能,例如文本规范化、短语/词/音节分割、词性标注、韵律预测、字素到音素的转换(包括多音字消歧)。在端到端模型中,只保留文本规范化和字素到音素的转换,将字符转换为音素,或者直接将字符作为输入,省略整个文本分析模块。2)简化声学特征,将在SPSS中使用的复杂声学特征(如MGC、BAP和F0)简化为梅尔频谱图。3)用单个端到端模型替换两个或三个模块。例如,声学模型和声码器可以被单个声码器模型(如WaveNet)替换。
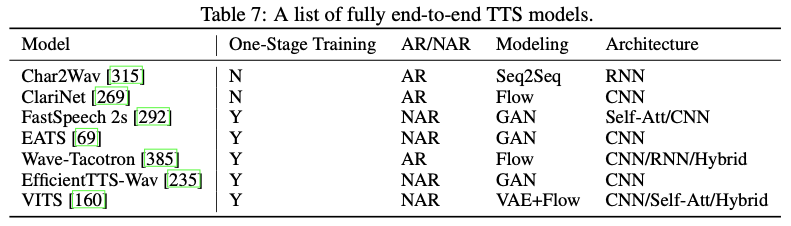
6. 其他分类
- 自回归或非自回归
- 生成模型:正常的序列生成模型、流模型、GAN、VAE和扩散模型
- 网络结构:CNN、RNN、自注意力和混合结构