论文笔记:TTS前沿课题
论文笔记:TTS前沿课题
论文原文地址:https://arxiv.org/abs/2106.15561
1. 背景
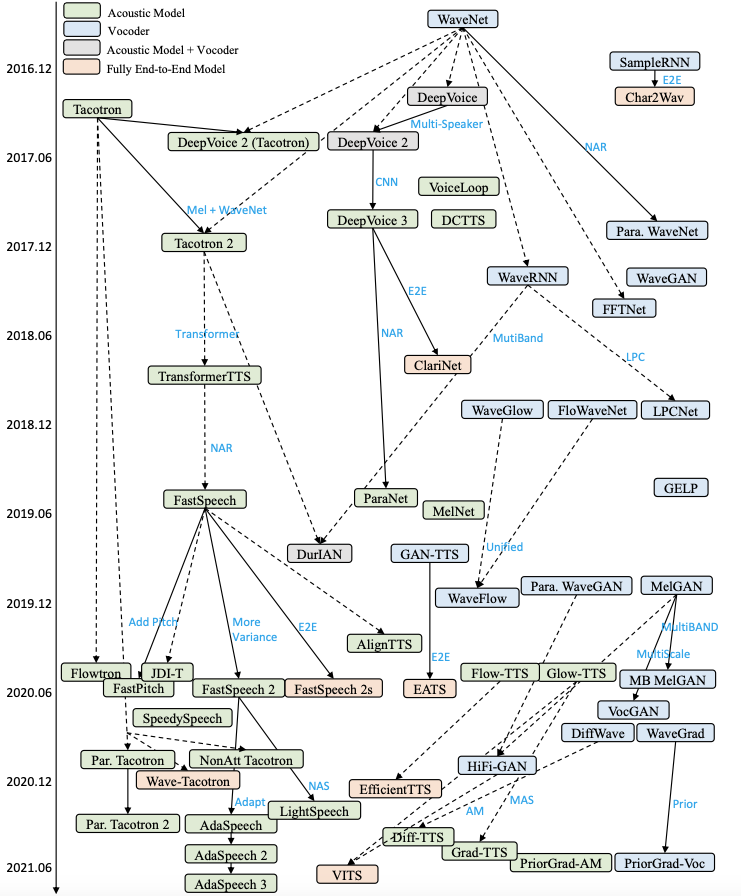
TTS是一种典型的Seq2Seq生成任务,自回归生成速度较慢。因此,如何加速自回归生成速度或减小模型大小以实现快速语音合成广受关注。此外,很多研究旨在提高语音合成的自然度和可理解性,尤其是在低资源环境下构建数据高效的TTS模型。由于TTS模型易出现鲁棒性问题,很多研究旨在提高语音合成的鲁棒性,减少跳字和重复。为了提高自然度,很多工作旨在对语音的风格/韵律进行建模、控制和转移,以生成富有表现旅的语音。下图为神经网络TTS模型的迭代过程。
什么是自回归:自回归是指在序列生成任务中,生成每个元素时都依赖于前面已生成的元素。具体来说,在自回归模型中,生成序列的每个元素都是通过条件概率模型来预测,而该模型的输入是已生成的前面的元素。在语音合成中的自回归模型中,生成语音的每个帧或每个音素依赖于之前已生成的帧或音素。模型会根据已生成的上下文信息来预测下一个帧或音素的概率分布,然后从该分布中采样得到下一个要生成的帧或音素。生成的序列会逐步延伸,直到生成整个语音信号。由于自回归生成需要按顺序生成每个元素,因此生成过程相对较慢,尤其是对于较长的序列。这是因为每个元素的生成都需要等待前面元素的生成结果。为了加速自回归生成过程,研究者们一直在探索各种方法,例如使用更高效的模型结构、采用并行化策略或者引入自回归生成的近似方法。
2. Fast TTS
文本到语音合成系统通常部署在云服务器或嵌入式设备中,需要快速的合成速度。然而,早期的神经语音合成模型通常采用自回归的梅尔频谱图和波形生成方法,考虑长语音序列(例如,如果hop size为10毫秒,则1秒的语音通常具有500个梅尔频谱图,如果采样率为24kHz,则具有24k个波形点),生成速度非常慢。为了解决这个问题,采用不同的技术来加速TTS模型的推理,包括:1)非自回归生成,可以并行生成梅尔频谱图和波形;2)轻量高效的模型结构;3)利用语音领域知识的技术,用于快速语音合成。
3. Low-Resource TTS
构建高质量的TTS系统通常需要大量高质量的文本和语音配对数据。然而,全球有超过7000种语言,大多数语言缺乏用于开发TTS系统的训练数据。因此,目前的商业化语音服务只能支持数十种语言进行TTS。支持低资源语言的TTS不仅具有商业价值,而且对社会有益。因此,很多研究工作在低数据资源场景下构建TTS系统。
自监督训练(Self-supervised Training)
尽管配对的文本和语音数据很难收集,但是非配对的语音和文本数据(尤其是文本数据)相对容易获取。可以利用自监督预训练方法来增强语言理解或语音生成的能力。例如,TTS中的文本编码器可以通过预训练的BERT模型来增强,而TTS中的语音解码器可以通过自回归的梅尔频谱图预测或与声音转换任务联合训练进行预训练。此外,可以将语音量化为离散的令牌序列,以模拟音素或字符序列。通过这种方式,量化的离散令牌和语音可以被视为伪配对数据,用于预训练TTS模型,然后在少量真正配对的文本和语音数据上进行微调。
跨语言迁移(Cross-lingual Transfer)
尽管低资源语言缺乏配对的文本和语音数据,但是在富资源语言中却很丰富。由于人类语言共享相似的发音器官、发音方式和语义结构,在富资源语言上对TTS模型进行预训练可以帮助低资源语言中的文本与语音之间的映射。通常,富资源语言和低资源语言之间存在不同的音素集。因此,一些工作提出了将不同语言的音素集之间的嵌入进行映射,而LRSpeech则放弃了预训练的音素嵌入,并从头开始初始化低资源语言的音素嵌入。国际音标(IPA)或字节表示被采用来支持多种语言中的任意文本。此外,在进行跨语言迁移时还可以考虑语言的相似性。
跨说话人迁移(Cross-speaker Transfer)
当某个说话人的语音数据有限时,可以利用其他说话人的数据来提高该说话人的合成质量。这可以通过将其他说话人的声音通过声音转换转换为目标声音来增加训练数据,或者通过声音适应或声音克隆来调整在其他声音上训练的TTS模型,以适应目标声音。
语音链/反变换(Speech Chain/Back Transformation)
文本到语音(TTS)和自动语音识别(ASR)是两个互为对偶的任务,可以共同利用来改善彼此的性能。类似语音链和反变换的技术利用额外的非配对文本和语音数据来提升TTS和ASR的性能。
数据集挖掘(Dataset Mining in the wild)
在某些情况下,可能存在一些低质量的配对文本和语音数据在网络上。一些技术如语音增强、降噪和解耦可以用来改善在野外挖掘的语音数据的质量。
4 Robust TTS
一个好的TTS系统应该具有鲁棒性,在遇到边缘情况时能生成正确的语音。在神经网络TTS中,鲁棒性问题经常由如下两种音素引起:字符/音素与梅尔频谱图之间对齐的难度;自回归生成中引起的暴露偏差和错误传播问题。 声码器不存在这些问题,因为声学特征和波形图已经以帧为单位对齐。
**对于字符/音素与梅尔频谱图之间对齐的学习,**该问题上的研究可以分为两类:加强注意力机制的鲁棒性;移除注意力机制,而是显式预测持续时间,以弥合文本和语音长度不匹配的问题。
**对于暴露偏差和错误传播,**该问题上的研究可以分为两类:改进自回归生成以减轻暴露偏差和错误传播;改用非自回归生成。
暴露偏差:Exposure bias是在Exposure bias是在自然语言处理(NLP)领域,尤其是序列生成任务中常见的一种问题。它涉及到训练模型和实际使用模型之间的差异。在训练序列生成模型(例如自回归模型)时,模型通常会看到完整的输入序列,然后预测每个位置的输出。但是,在实际使用这些模型时,模型需要在每个步骤生成一个输出,并将这个输出用作下一个步骤的输入。
这种训练和实际使用之间的不匹配称为“exposure bias”。在训练过程中,模型“暴露”于完整且正确的输入序列,但在实际使用中,模型必须处理其自身生成的可能不完美的输出。因此,模型可能会在实际使用中遇到一些在训练过程中从未见过的情况,这可能导致模型的性能下降。
4.1 Enhancing Attention
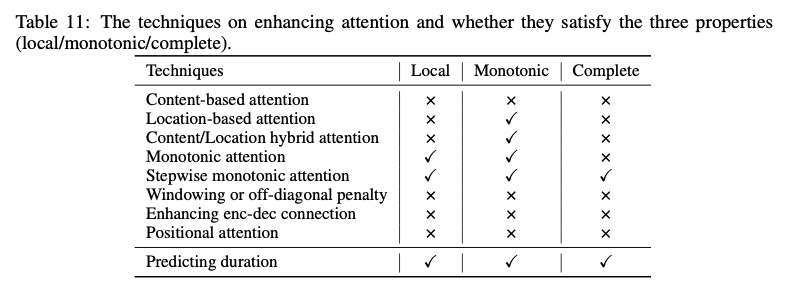
在自回归声学模型中,由于编码器-解码器注意力学习的不正确对齐,会导致很多单词跳过/重复和注意力崩溃问题。为了缓解这个问题,考虑文本(字符/音素)序列与梅尔频谱图序列之间的对齐属性:1)局部性:一个字符/音素令牌可以与一个或多个连续的梅尔频谱图帧对齐,而一个梅尔频谱图帧只能与一个字符/音素令牌对齐,这可以避免模糊的注意力和注意力崩溃;2)单调性:如果字符A在字符B之后,与A对应的梅尔频谱图也在与B对应的梅尔频谱图之后,这可以避免单词的重复;3)完备性:每个字符/音素令牌必须由至少一个梅尔频谱图帧覆盖,这可以避免单词的跳过。下图为多种增强注意力技术的介绍:
4.2 Replacing Attention with Duration Prediction
尽管改进文本和语音之间的注意力对齐可以在一定程度上缓解鲁棒性问题,但并不能完全避免。因此,一些研究工作提出了完全去除编码器-解码器注意力的方法,显式地预测每个字符/音素的持续时间,并根据持续时间扩展文本隐藏序列以匹配梅尔频谱图序列的长度。在此之后,模型可以以自回归或非自回归的方式生成梅尔频谱图序列。有趣的是,早期的SPSS使用持续时间进行对齐,然后序列到序列模型去除了持续时间但使用了注意力,而后来的TTS模型再次舍弃了注意力而使用持续时间,这是一种技术的复兴。
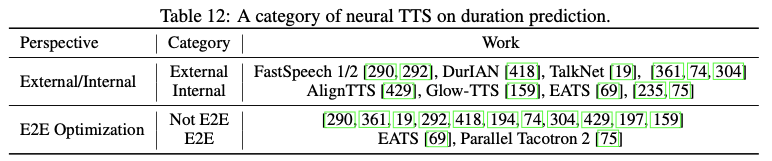
现有的用于研究神经TTS中持续时间预测的工作可以从两个角度进行分类:1)使用外部对齐工具或联合训练来获得持续时间标签;2)通过端到端的方式优化持续时间预测,或在训练中使用地面实况持续时间,在推断中使用预测的持续时间。下图为相关工作的总结:
4.3 Enhancing AR Generation
自回归序列生成通常受到暴露偏差和错误传播的影响。一些研究工作已经探索了不同的方法来缓解暴露偏差和错误传播问题:利用教授强制方法(professor forcing)缓解真实数据和预测数据之间的分布差异;利用教师-学生蒸馏(teacher-student distillation)以减少暴露偏差问题,其中教师模型以教师强制模式训练,学生模型以先前的预测值作为输入,并优化隐藏状态之间的距离以减小教师和学生模型之间的差异。考虑到由于错误传播,生成的梅尔频谱图序列的右侧通常比左侧更差,一些研究工作利用从左到右和从右到左的生成进行数据增强和正则化;利用一些数据增强方法来缓解暴露偏差和错误传播问题,通过向每个输入频谱图像素添加一些随机高斯噪声来模拟预测错误,并通过随机替换几个帧与随机帧以鼓励模型使用时间上更远的帧来降低输入频谱图的质量。
Teacher-student distillation,有时也被称为知识蒸馏,是一种训练神经网络的技术。它涉及两个模型:一个通常较大、较复杂且性能较好的模型(称为"teacher"),以及一个较小、较简单且性能较低的模型(称为"student")。知识蒸馏的目标是让student模型学习和模仿teacher模型的行为。这通常通过让student模型尝试复制teacher模型的输出概率分布来实现。这种方式可以使student模型从teacher模型那里获取到更丰富的信息,而不仅仅是从数据标签中获取信息。
因此,这种方法有助于改善student模型的性能,让其能更好地泛化到新数据,同时还保留了其相对较小和计算效率较高的优点。这在需要轻量级模型(例如,在移动设备或嵌入式系统上运行)的情况下尤其有用。
4.4 Replacing AR Generation with NAR Generation
尽管通过上述方法可以缓解自回归生成中的暴露偏差和错误传播问题,但这些问题无法完全解决。因此,一些工作直接采用非自回归生成来避免这些问题。根据是否使用注意力或持续时间预测,它们可以分为两类。一些工作在并行生成中使用位置注意力来进行文本和语音的对齐。其他工作使用持续时间预测来弥合文本和语音序列之间的长度不匹配。
根据上述小节的介绍,我们根据对齐学习和自回归/非自回归生成将TTS划分为了一个新的类别,如表13所示:1)自回归 + 注意力,例如Tacotron、DeepVoice 3和TransformerTTS。2)自回归 + 非注意力(持续时间),例如DurIAN、RobuTrans和Non-Attentive Tacotron。3)非自回归 + 注意力,例如ParaNet、Flow-TTS和VARA-TTS。4)非自回归 + 非注意力,例如FastSpeech 1/2、Glow-TTS和EATS。
5 Expressive TTS
文本到语音的目标是合成可理解和自然的语音。自然度在很大程度上取决于合成声音的表现力,这由多个特征决定,例如内容、音色、语调、情感和风格等。Expressive TTS的研究涵盖了广泛的主题,包括对内容、音色、语调、风格和情感等进行建模、解耦、控制和转移。
Expressive TTS的关键是解决一对多映射的问题,这指的是对于相同文本,存在多个与之对应的语音变体,如持续时间、音高、音量、说话者风格、情感等。在没有足够的输入信息的情况下,通过常规的L1损失函数建模一对多映射会导致过度平滑的梅尔频谱图预测,例如,预测数据集中的平均梅尔频谱图,而不是捕捉每个语音表达的表现力,这会导致质量低下且表现力不足的语音。因此,将这些变化信息作为输入并更好地建模这些变化信息对于缓解这个问题和提高合成语音的表现力非常重要。此外,通过将变化信息作为输入提供,我们可以解耦、控制和转移这些变化信息:1)通过在推理中调整这些变化信息(特定的说话人音色、风格、口音、语速等),我们可以控制合成语音;2)通过提供与另一种风格相对应的变化信息,我们可以将声音转移到该风格;3)为了实现精细的语音控制和转移,我们需要解耦不同的变化信息,如内容和语调、音色和噪声等。
6 Adaptive TTS
自适应TTS是TTS的一个重要特性,可以为任何用户合成语音。在学术界和工业界,它被称为不同的术语,如语音适应、语音克隆、自定义语音等。自适应TTS一直是一个热门的研究课题,例如,许多统计参数语音合成的研究工作已经研究了语音适应 ,而最近的语音克隆挑战也吸引了许多参与者。在自适应TTS的场景中,通常使用少量的适应数据对源TTS模型(通常在多说话人语音数据集上训练)进行调整,以适应每个目标语音。
在自适应TTS的研究中,我们从两个角度进行回顾:1)一般适应设置,涵盖了改进源TTS模型的泛化能力以支持新说话人,以及适应不同领域。2)高效适应设置,涵盖了减少每个目标说话人的适应数据和适应参数。