FastSpeech2 论文笔记(不包含FastSpeech2s)
FastSpeech2 论文笔记(不包含FastSpeech2s)
原文地址:https://arxiv.org/abs/2006.04558
1. 简介
FastSpeech 存在一些缺点:教师-学生蒸馏流程复杂且耗时;从教师模型中提取的持续时间不够准确;从教师模型蒸馏出的目标梅尔频谱图有信息丢失等。因此,FastSpeech2直接使用真实语音作为训练目标,而不是教师模型的简化输出;引入了更多的语音变化信息作为条件输入。实验结果表明,FastSpeech2相比FastSpeech实现了三倍的训练加速,推理更快,且合成质量优于FastSpeech。
TTS(文字到语音,Text-To-Speech)任务是一个典型的一对多合成问题。由于语音的变化,如音调、持续时间、音量、韵律,一个文本序列可能对应多个语音序列。在非自回归TTS模型中,文字序列是唯一的输入,导致模型无法预测语音的变化,可能导致过度拟合训练样本上的语音变化而降低泛化能力。FastSpeech2旨在解决这些问题。
2. FastSpeech2 模型宏观结构
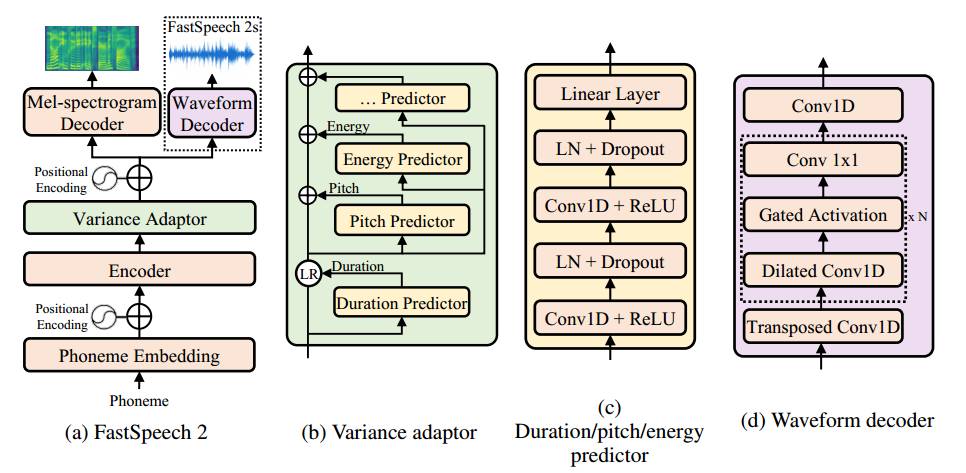
如图所示为FastSpeech2的模型结构。其中FastSpeech2s是一个完全端到端模型(不包括生成的梅尔频谱图中间量以及后续的声码器)。
编码器(Encoder)将音素(Phoneme)嵌入序列转换为音素隐藏序列,然后“变化适配器(Variance Adaptor)”将不同的语音变化信息添加到隐藏序列中,如:持续时间(Duration),音高(Pitch)以及能量(Energy)。最后,解码器(Mel-spectrogram Decoder)将隐藏序列转为梅尔频谱序列。该模型使用前馈Transformer块作为编码器和解码器的基本结构,该块是自注意力层和1D卷积层的堆叠。该模型使用的Variance Adaptor中,持续时间预测器(Duration Predictor)通过强制对齐获得的音素持续时间作为训练目标。此外,额外的音高和能量预测器可以提供更多的变化信息,以缓解TTS中的一对多问题。
3. Variance Adaptor 变化适配器
Variance Adaptor的目标是向隐藏序列中添加变化信息。这些变化信息包括:**Duration:**表示语音声音的持续时间;**Pitch:**音调,是传达情感的关键特征,极大地影响语音韵律;**Energy:**能量,表示梅尔频谱图的帧级幅度,影响语音的音量和韵律。Variance Adaptor可以添加更多的方差信息,如说话人、情感、风格等。在训练中,模型从训练数据中提取持续时间、音调和能量的真实值作为输入,用于预测目标语音。同时,以这些真实的变化信息为目标,训练Duration Predictor、Pitch Predictor以及Energy Predictor组件。这些预测器组件在推理中用于合成目标语音。
如上图(c)所示,Duration/Pitch/Energy Predictor具有相同的模型结构(模型参数不同),包括一个ReLU激活函数的2层1D卷积网络,每个卷积网络后跟随曾归一化和Dropout层。最终,尾部有一个线形层将隐藏状态投影到输出向量。
3.1 Duration Predictor
Duration Predictor 以音素隐藏序列作为输入,并预测每个音素的持续时间,表示该音素对应的梅尔帧数。为了便于预测,将其转换为对数域。Duration Predictor使用均方误差损失(MSE)进行优化,以从训练样本中提取的持续时间作为训练目标。为了提高准确性,使用Montreal Forced Aligner(MFA)工具对原始数据进行强制对齐,并提取音素的持续时间。
3.2 Pitch Predictor
为了更好地预测音调轮廓的变化,FastSpeech2采用连续小波变换(Continuous wavelet transform,CWT)将连续音调分解为音调谱图,并将音调谱图作为音调预测器的训练目标。Pitch Predictor 采用MSE进行优化,在推理中,音调预测器预测音调谱图,然后使用逆CWT将其转换为音调轮廓。
为了在训练和推理中将音调轮廓作为输入,将每帧的音高F0量化为对数刻度上的256个可能值,并将其转换为音调嵌入向量p,添加到隐藏序列中。
3.3 Energy Predictor
通过计算每个短时傅里叶变换(Short-time Fourier Transform,STFT)帧的振幅的L2范数来计算能量,然后,将每帧的能量化为256个均匀分布的可能值,并将其编码为能量嵌入e,并将其类似地添加到扩展的隐藏序列中。Energy Predictor使用MSE进行优化。
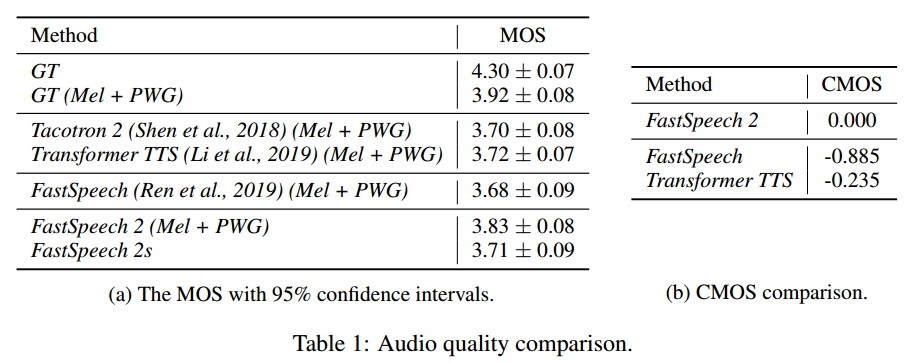
4. 实验结果
在LJSpeech数据集上评估FastSpeech2,根据采样率22050设置帧大小(frame size)和跳跃大小(hop size)设置为1024和256。在Encoder和Decoder中包括4个前馈变换器(FFT)块。解码器中的输出线性层将隐藏状态转换为80维的梅尔频谱图。模型使用MAE进行优化,结果如下图: