论文笔记:NaturalSpeech2
NaturalSpeech2: Latent Diffusion Models are Natural and Zero-Shot Speech and Singing Synthesizers
原文地址:https://speechresearch.github.io/naturalspeech2/
Abstract
本文介绍了一种名为 NaturalSpeech 2 的TTS系统,旨在解决 large-scale、Multi-speaker 和 in-the-wild 数据集上的 TTS 任务。它采用神经音频编解码器和扩散模型,以实现更稳定的韵律、避免跳词/重复问题,并提高声音质量。为了实现零样本能力,作者还设计了一种语音提示机制(speech prompting mechanism)。经过在具有大规模语音和歌唱数据的数据集上的评估,NaturalSpeech 2 在 Zero-shot 情况下表现出色,包括韵律/音色相似性、稳健性和声音质量方面均优于先前的TTS系统。此外,该系统还实现了 Zero-shot 歌唱合成的新功能。
Background
传统的 TTS 系统通常利用神经编码器将语音波形转换为离散标记序列(Discrete token sequence),并使用自回归语言模型从文本生成离散标记,但存在以下问题:
- 使用 Vector-quantizer:序列长度短,使语言模型中的标记生成变得容易,但压缩率大、比特率低。
- 使用 Residual Vector-quantizer:序列长度增加,自回归模型生成困难(错误传播和鲁棒性),高保真。
因此,NaturalSpeech2 采用连续向量和非自回归生成的 Latent Diffusion Model 的神经编码器。
传统的音频编解码器所生成的中间表示(Compact representations)用于音频的传输,通常以压缩率作为关键指标。但这种编解码器不一定适合生成机器学习的中间量。因此,NaturalSpeech2 设计了一个神经音频编解码器,将语音波形转换为连续向量,而不是离散标记,这可以在不增加序列长度的情况下保持足够精细的细节,以进行精确的波形重构。
自回归模型更加敏感于序列长度和错误传播,这会导致鲁棒性变差。因此NaturalSpeech2利用了加强了 Duration Prediction 和 Length Prediction 以及 Length Expansion 的扩散模型,提升鲁棒性。
NaturalSpeech2
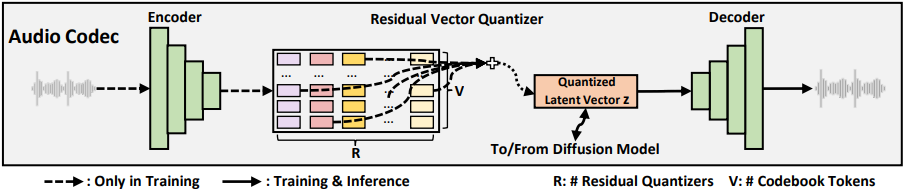
Encoder:编码器,从音频波形中提取帧级别的语音表示。
RVQ 残余向量量化器:利用多个 codebooks 量化帧级别表示。
Decoder:将量化的向量重构成音频波形,量化的向量还作为 Latent Diffusion Model 的训练目标。
神经音频编解码器的工作流程如下:
其中,x是语音波形,h是通过音频编码器获得的具有n帧长的隐藏序列,z是与h长度相同的量化向量序列。i 是语音帧的索引,j 是残差量化器的索引,R 是残差量化器的总数,e ^ i _ j是通过第 j 个残差量化器在第 i 个隐藏帧(即 hi)上获得的码本 ID 的嵌入向量。
Speech Prompt
为了更好地进行 Zero-shot 生成,NaturalSpeech2设计了一种语音提示机制,以鼓励 Duration Predictor,Pitch Predictor 和 Diffusion 模型遵循语音提示中的多样性信息(例如:说话者身份)。对于一个 Quantized Latent Vector Z,随机切割一个从 u 到 v 帧的帧索引段作为 Prompt,并将剩余的语音段(1:u)和(v:n)连接成一个新的语音序列,作为 Diffusion 模型的学习目标。