TTS 情感控制:Fine-Grained Emotional Control of Text-To-Speech: Learning To Rank Inter- And Intra- Class Emotion Intensities
原文地址:arXiv: Fine-grained Emotional Control of Text-To-Speech: Learning To Rank Inter- And Intra-Class Emotion Intensities
概述
近年来,端到端的TTS模型能够合成具有中性情感(Neutral)的高质量语音,然而,这些模型在表达情感等信息方面存在局限性。实现情感控制的一种直接策略是通过对全局情感标签进行Conditioning来表达不同的情感,或使用单个token或向量组来表示情感信息。这些模型往往难以捕捉参考语音中的细微差别,这是由于参考内容或说话者与合成语音之间的不匹配导致的。这进一步导致了对合成语音的控制能力差。
实现语音控制的TTS的更好方法是在单词(Words)或音素(Phonemes)上手动分配强度标签。在一些使用强度标签控制语音情感的工作中,其基本假设是:1)来自同一情感类别的语音样本具有相似的排名;2)中性情感的强度最弱,而其他所有情感的排名高于中性情感。尽管这些方法能够生成具有不同情感强度水平的可识别的语音样本,但它们忽视了类内距离,简单地将同一类别(即使具有不同的情感强度)的样本归为相同。
本文(Fine-Grained Emotional Control of Text-To-Speech)提出了一种TTS模型,基于Rank模型,通过同时考虑类间和类内距离提取情感信息。通过使用Mixup增强的两个样本,每个样本都是来自相同非中性和中性语音的混合。通过对非中性和中性语音应用不同的权重,一个Mixture中的非中性语音成分要比另一个Mixture中的多。通过让模型学习对这两个Mixture进行排名,该模型不仅要能确定情感类别(类间距离),还必须能够捕捉Mixture中非中性情感的数量(类内距离)。
Mixup: Beyond Empirical Risk Minimization
原文链接:arXiv
Rank Model

如上图所示为 Rank Mode 的结构,它将语音映射为强度表示,然后根据情绪强度输出排名分数。输入X是梅尔频谱图,音高轮廓和能量的串联。Xnue 是中性语音的输入,Xemo 是非中性语音的输入。在这之后,对配对的(Xnue, Xemo)进行Mixup处理:
Xmixi=λiXemo+(1−λi)XneuXmixj=λjXemo+(1−λj)XneuWhere λi and λj are from Beta distribution Beta(1,1)
Intensity Extractor(强度提取器)随后被用于提取强度表示。它首先经过与FastSpeech2相同的前馈变换器FFT处理输入。情感信息随后被嵌入到FFT的输出中,以产生强度表示 Imixi,Imixj。这些嵌入来自于一个查找表,并取决于 Xemo 的情感类别。从强度表示 Imixi 和 Imixj 中,将这两个序列平均为两个向量 hmixi 和 hmixj ,然后在它们上进一步应用原始的Mixup损失:
Lmixup=Li+Lj whereLi=λiCE(hmixi,yemo)+(1−λi)CE(hmixi,yneu),Lj=λjCE(hmixj,yemo)+(1−λj)CE(hmixi,yneu),
其中,CE表示Cross Entropy loss交叉熵损失,yemo 表示非中性情感的 label,yneu 表示中性情感的 label。
Mixup不一定能很好地表征类内距离,因此,引入另一个loss来表征这种关系。首先,使用一个投影(线性)将配对的 (hmixi , hmixj) 映射到一个标量对 (rmixi , rmixj) ,其中 rmix∈R1。rmix 是一个提示语音中非中性情感存在程度的得分,即强度。为使模型能够正确预测分数,首先将分数差输入到一个Sigmoid函数中:
Pij=1+e−(rmixi−rmixj)1
之后,在其上应用 Rank Loss:
Lrank=−λdifflog(pij)−(1−λdiff)log(1−pij)
其中 λdiff 是 λi−λj 的归一化结果。即:如果 λi>λj ,则 λdiff∈(0.5,1);如果 λi<λj ,则 λdiff∈(0,0.5);如果 λi=λj ,则 λdiff=0.5。
最后,使用总损失 total loss 来训练模型:
Ltotal=αLmixup+βLrank
其中 α 和 β 是损失权重。
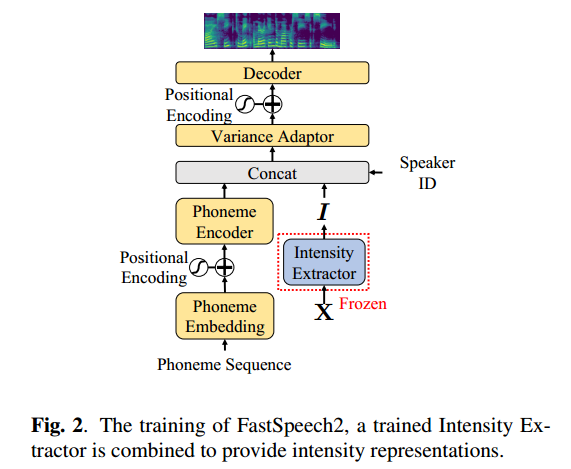
TTS Model
保留 FastSpeech2 的基本结构,将 Intensity Extractor 与 Encoder 的输出结合,并输入 Variance Adaptor
FastSpeech2: Fast And High-Quality End-To-End Text To Speech
原文链接:arXiv
本站文章链接:https://aucki6144.github.io/2023/09/16/FastSpeech2笔记/