NExT-GPT:Any-to-Any Multimodal LLM 任意到任意的多模态LLM系统
NExT-GPT:Any-to-Any Multimodal LLM 任意到任意的多模态LLM系统
原文地址:https://arxiv.org/abs/2309.05519
项目地址:https://next-gpt.github.io/
NExT-GPT能够以任意文本、图像、视频和音频的组合感知输入并生成输出。
概述 Overall
如图所示,NExT-GPT 包括三个层次。首先,利用已建立的编码器对各种模态的输入进行编码。其中,这些表示通过投影层映射为 LLM 可以理解的类似语言的表示。其次,利用现有的开源 LLM 作为核心, 处理输入信息,进行语义理解和推理。LLM 不仅直接生成文本标记,还产生独特的“模态信号”标记,用作指示解码层输出相应的模态内容。优于 NExT-GPT 涵盖了各种模态的编码和生成,从头开始训练将导致巨大的训练成本。因此,NExT-GPT 利用了现有的预训练高性能编码器和解码器,例如:Q-Former、ImageBind和最先进的 Latent Diffusion 模型。
为了实现三个层次之间的特征对齐,NExT-GPT 仅在输入投影和输出投影层上进行局部微调,采用编码端 LLM 为中心的对齐和解码端遵循指令的对齐。此外,引入了模态切换指令调整(Modality-switching instruction tuning, Mosit),为系统提供复杂的跨模态语义理解和内容生成能力。
NExT-GPT 的工作可以总结如下:
- 首次提出了一种端到端的通用任意到任意的 MM-LLM 模型,能够进行语义理解、推理以及生成文本、图像和音频的自由输入输出组合。
- 引入了轻量级对齐学习技术,编码端的以LLM为中心的对齐和解码端的遵循指令对齐,基于最小的参数调整实现有效的语义对齐。
- 标注了一个高质量的 Mosit 数据集,涵盖了文本、图像、视频和音频的各种模态组合的复杂指令。
结构 Architecture
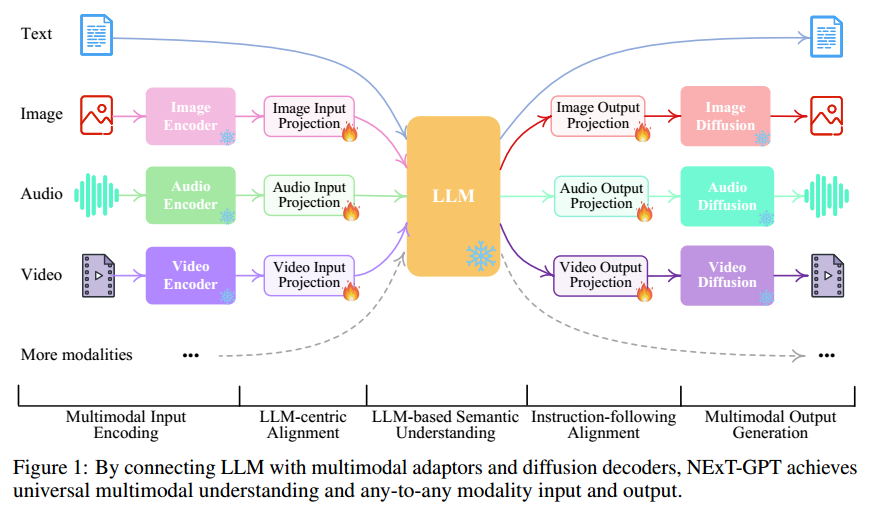
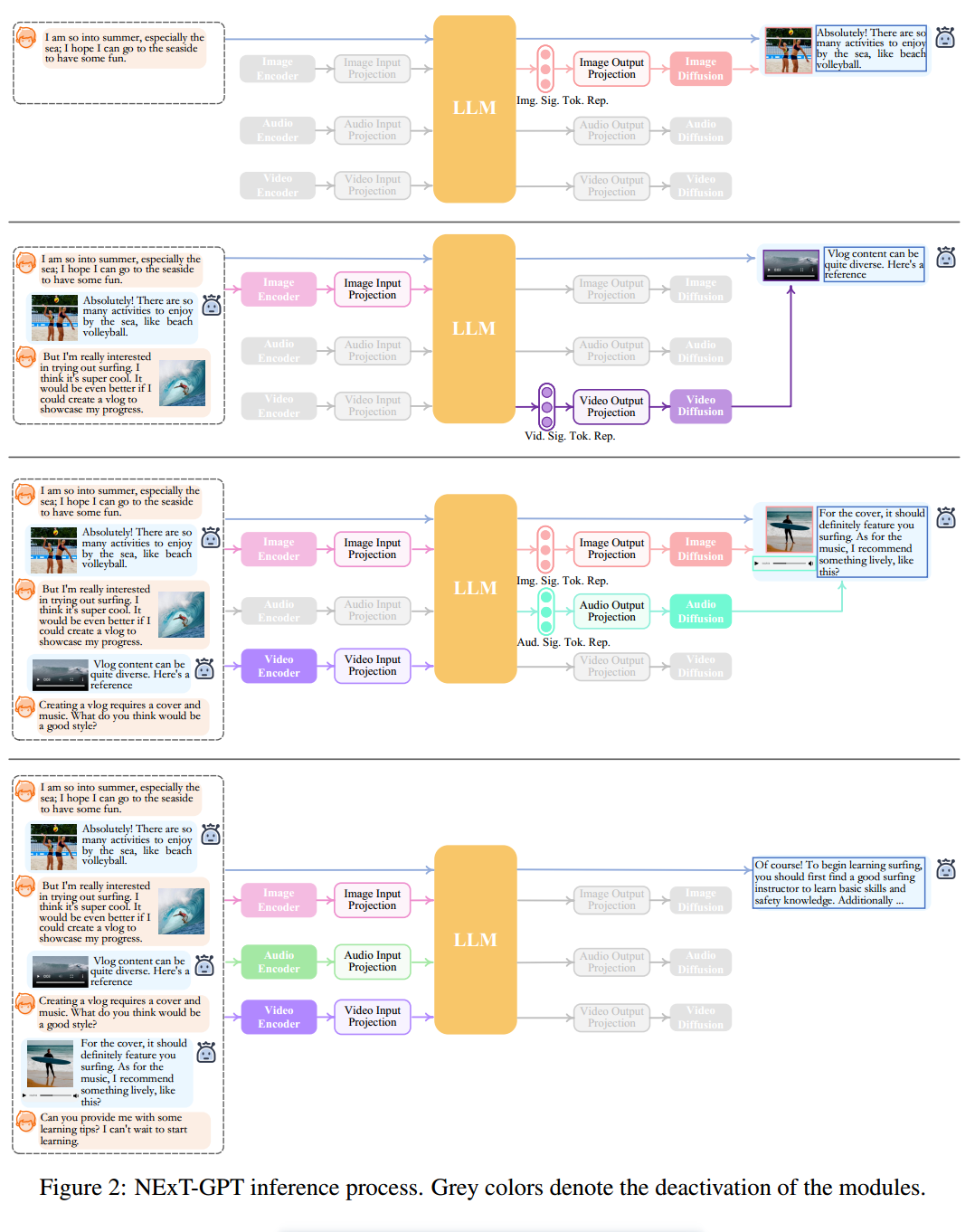
上图 Figure1 展示了 NExT-GPT 的概要示意图。NExT-GPT 由三个主要层次组成:编码阶段、LLM 推理、解码阶段。
编码
首先,利用现有的成熟模型对各种模态的输入进行编码。对于不同的模态,有一系列可选的编码器。例如:QFormer,ViT,CLIP。NExT-GPT 采用了 ImageBind 处理六种模态的输入,它是一个统一的高性能编码器。然后,通过线性层将不同的输入表示映射为 LLM 可以理解的类似语言的表示。
LLM 理解以及推理
NExT-GPT 采用 Vicuna2,这是一个开源的基于文本的 LLM,在现有的多模态 LLM 中被广泛使用。它接受来自不同模态的表示作为输入,并对输入语义进行理解和推理。它直接输出文本相应和每个模态的信号令牌,这些令牌作为指令传达给解码层,告诉其是否生成多模态内容,以及如果是的话该生成什么内容。
多模态生成
接收来自 LLM 的信号后,基于 Transformer 的输出投影层将信号令牌表示映射为可被后续多模态解码器理解的表示形式。从技术上讲,NExT-GPT 采用了当前现成的不同模态生成的 Latent Conditioned Diffusion 模型,即用于图像合成的 Stable Diffusion (SD),用于视频合成的 Zeroscope4,以及用于音频合成的 AudioLDM5。信号表示被前馈到扩散模型的条件编码器中用于内容生成。
在下表中,总结了整个系统的配置。Note:在整个系统中,只有较低规模参数的输入输出投影曾需要在学习过程中进行更新,而其它所有组件的参数都被冻结。
ImageBind: One Embedding Space To Bind Them All arXiv
轻量级多模态对齐学习
为了弥合不同模态特征空间的差距,并确保对不同输入的流畅语义理解,对 NExT-GPT 来说,进行对齐学习是至关重要的,由于设计了有三个层级组成的松耦合系统,因此只需要更新编码端和解码端的两个线性层。
编码端
遵循现有工作的常规做法,考虑将不同输入的多模态特征与文本特征空间进行对齐。为实现对齐,从现有语料库和基准数据中准备了“X-caption”对。其中,X 代表图像、音频或视频。我们强制 LLM 根据 gold caption 为每个输入模态生成描述。
解码端
在解码端已经整合了预训练的条件扩散模型。主要目的是将扩散模型与 LLM 的输出指令对齐。这里采用了被称为“解码端指令跟随对齐”的方法。具体来说,由于各种模态的扩散模型仅仅以文本标记输入为条件。这种条件与我们系统中 LLM 的模态信号标记有显著差异。因此,考虑最小化 LLM 的模态信号标记表示(在每个基于 Transformer 的投影曾之后)与扩散模型的条件文本表示之间的距离。由于仅使用条件文本编码器,学习仅基于纯粹的文本,确保了轻量级的训练。
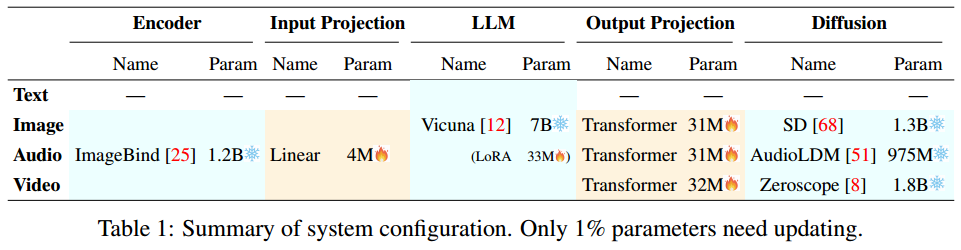
模态切换指令调整
为使整个系统能够理解用户的指令并生成所需的多模态输出,进一步的指令调整(Instruction Tuning, IT)被认为是增强 LLM 可控性的必要手段。IT 使用 输入-输出 对对整体的 MM-LLM 进行额外的训练。其中“输入”表示用户的指令,“输出”表示符合给定指令的期望模型输出。从技术上讲,NExT-GPT 利用 LoRA 在 IT 阶段的两个投影层同时更新参数,如下图所示。