PySpark 06 - Spark Partitions
PySpark 06 - Spark Partitions
RDDs are stored in partitions. Programmer specifies number of partitions for an RDD (Default value used if unspecified). More partitions means more parallelism but also more overhead.
- RDDs are stored in partitions. When performing computations on RDDs, these partitions can be operated on in parallel.
- You get better parallelism when the partitions are balanced.
- When RDDs are first created, the partitions are balanced.
- However, partitions may get out of balance after certain transformations.
In the following example of generating prime numbers:
1 | n = 500000 |
allnumbers is balanced partitions.
flatmap blows up each element into different numbers of elements, turning it into an RDD with partitions having very different sizes. This is why one partition had most of the data and took the greatest amount of time.
prime is balanced.
To fix this unbalance, repartition can be used:
1 | composite = allnumbers.flatMap(lambda x: range(x*2, n, x)).repartition(8) |
Properties of partitions
- Partitions never span multiple machines, i.e., tuples in the same partition are guaranteed to be on the same machine.
- Each machine in the cluster contains one or more partitions.
- The number of partitions to use is configurable. By default, it equals the total number of cores on all executor nodes (except when load an RDD from an HDFS/WASB file).****
Two kinds of partitioning available in Spark
- Hash partitioning.
- Range partitioning.
Hash Partitioning
Back to the prime number of example, we can view the contents of each partition of prime:
1 | print(prime.glom().collect()[1][0:4]) |
We can see the output:
1 | [17, 97, 113, 193] |
We see that it hashed all numbers x such that x mod 16 = 1 to partition #1
In general, hash partitioning allocates tuple (k, v) to partition p where .
When checking the number of partitions of
prime, the output will be 16:[0, 5169, 1, 5219, 0, 5206, 0, 5189, 0, 5165, 0, 5199, 0, 5191, 0, 5199]
That’s because the subtract operation is implemented with union by spark. Leading to number of partitions = 8 + 8 = 16.
Range Partitioning
For data types that have or ordering defined (Int, Char, String, … ). Internally, Spark samples the data so as to produce more balanced partitions.
Range Partitioning is used by default after sorting.
Partitioner
(key, value) pair RDDs that are the result of a a transformation on a partitioned Pair RDD typically is configured to use the hash partitioner that was used to construct it.
Some operations on RDDs automatically result in an RDD with a known partitioner - for when it makes sense. For example, by default, when using sortByKey, a Range Partitioner is used. Furtherm the default partitioner when using groupByKey, is a Hash Parititoner.
Partitioning Data: Custom Partition Function
Invoking partitionBy creates an RDD with a custom partition function. It also can be used to specify the partition function in transformations like reduceByKey, groupByKey. This can be useful when the default partition function doesn’t work well.
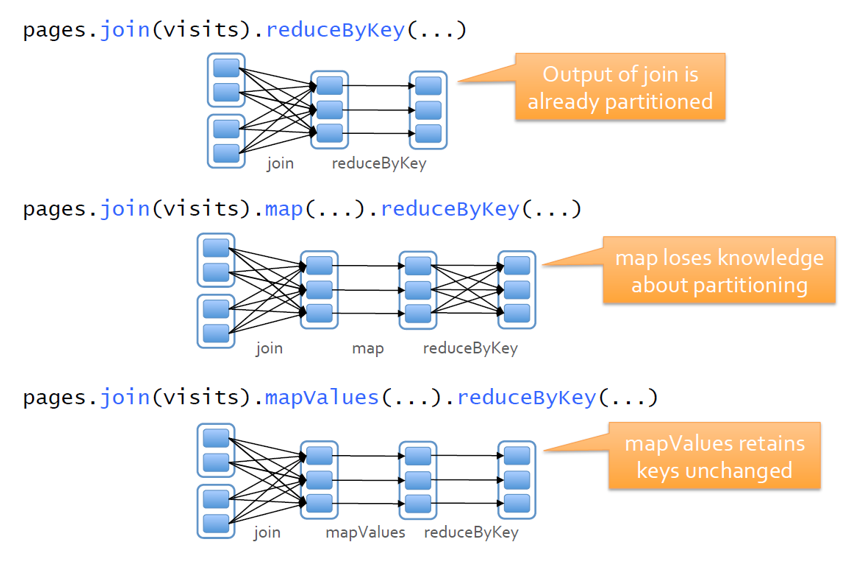
Operations on Pair RDDs that hold to (and propagate) a partitioner
- mapValues (if parent has a partitioner)
- flatmapValues (if parent has a partitioner)
- filter (if parent has a partitioner)
All other operations will produce a result without a partitioner.
Example