PySpark 07 - Spark Job Scheduling
Spark: Job Scheduling
Operations on RDDs
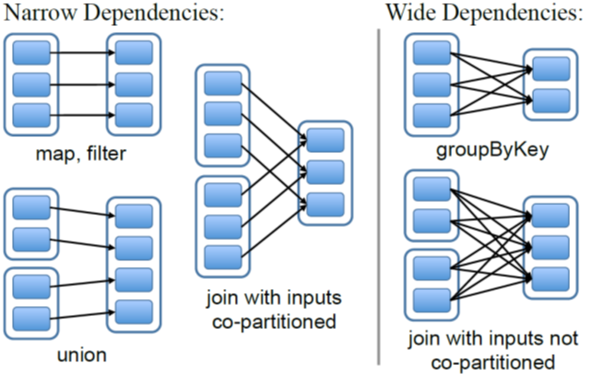
Narrow Dependencies and Wide Dependencies
HDFS files: Input RDD, one partition for each block of the file.
Map: Transforms each record of the RDD.
Filter: Select a subset of records.
Union: Returns the union of two RDDs.
Join: Narrow or wide dependency.
The scheduler examines the RDD’s lineage graph to build a DAG of stages. The boundaires are the shuffle stages. Pipelined parallel execution within one stage.
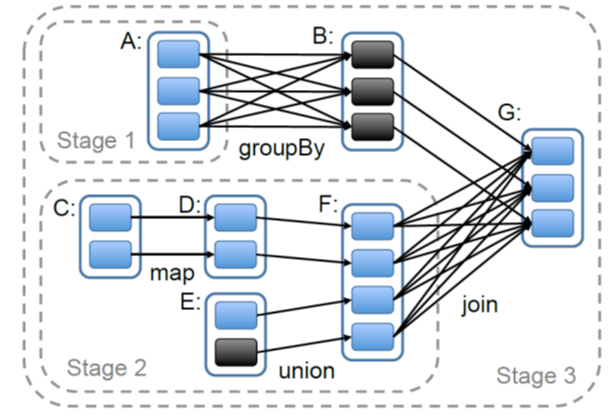
Shuffle operations
Spark uses shuffles to implement wide dependencies. (Example: reduceByKey, repartition, coalesce, join (on RDDs not artitioned using the same partitioner)). Spark generates sets of tasks - map tasks to organize the data, and a set of reduce tasks to group/aggregate it. Internally, Spark builds a hash table within each task to perform the grouping. If the hash table is too large, Spark will spill these tables to disk ,incurring the additional overhead of disk I/O. RDDs resulting from shuffles are automatically cached.
Example: join order optimization
Have three tables:
- Waybills (waybill, customer). Partitioned by waybill.
- Customers (customer, phone). Partitioned by customer.
- Waybill_status (waybill, version). Partitioned by waybill.
To join them together,
1 | # We want to join 3 tables together. |
Line 5 has a better efficiency than Line 4.
Job Scheduling
Job: a Spark action and any tasks that need to run to evaluate that action.
Multiple parallel jobs can run simultaneously if they a re submitted from separate threads.
Spark’s schedule runs job in FIFO fashion
- Also possible to configure fair sharing between jobs, i.e., round robin.
- Aso supports Scheduler Pools.
Task Scheduling Within a Job
Each job consists of multiple stages.
A stage can only start after all its parents stages have completed.
Each stage has many tasks.
Spark assigns tasks to machines based on data locality. If a task needs to process a partition that is available in memory on a node, we send the code of the task to that node.
Different levels of locality are used:
- PROCESS_LOCAL data is in the same JVM as the running code.
- NODE_LOCAL data is on the same node.
- RACK_LOCAL data is on the same rack of servers.
- ANY.
Two types of memory usages for applications:
- Execution memory: for computation in shuffles, joins, sorts and aggregations.
- Storage memory: for caching and propagating internal data across the cluster.
Execution and storage share a unified region (M). By default, it’s 0.6 * (total memory available to JVM - 300MB). Execution may evcit storage if necessary. But storage memory is guaranteed to be ≥ R, default R = 0.5 * M. Storage may not evict execution.
Remakes:
Applications that do not use caching can use the entire memory space for execution.
Applications that do use caching can reserve a minimum storage space ®.